Top 5 mistakes in IT monitoring

A
Hey! I'm an Azure and DevOps enthusiast, PowerShell chaos monkey, avid reader and blogger. Helping people move to the Cloud.
Search for a command to run...
No comments yet. Be the first to comment.
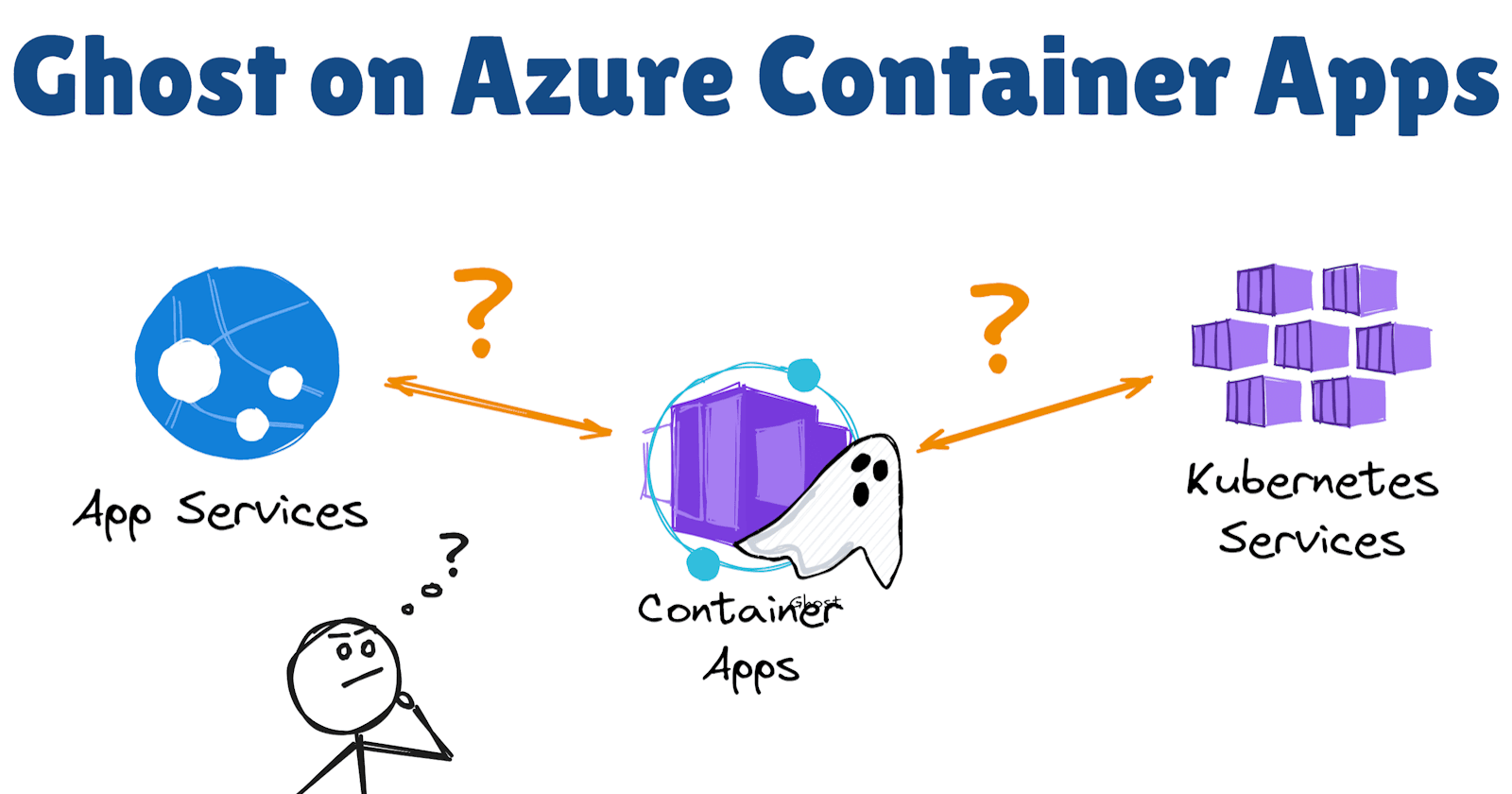
If you have been following my experiments for hosting and running Ghost on Azure, you might recall that I tried hosted it on Azure Web App for Containers first, using the Docker Compose for running a
I recently presented on a webinar hosted by the Turbo360 team and Michael Stephenson, the host of Azure on Air and FinOps on Azure podcasts. There, we discussed the most common mistakes in optimizing compute costs in Azure and how to avoid them, the ...

I’ve been watching the development of Radius, a new application hosting platform that originated in the Microsoft Azure Incubations team and later became a CNCF project, for a while, and I finally managed to dedicate some time to trying it in practic...

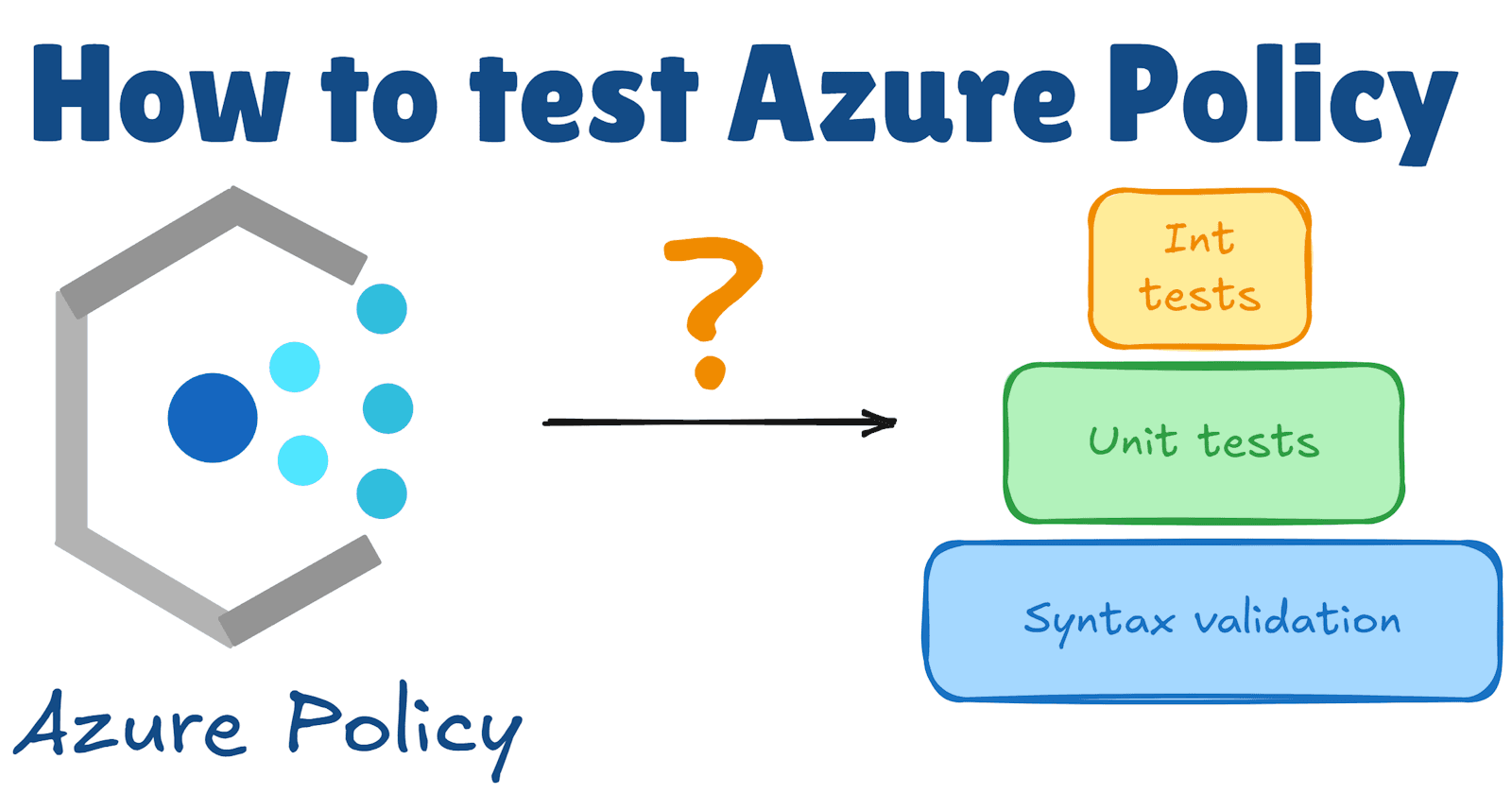
It has been some time since I wrote my Azure Policy Starter Guide, in which I briefly touched upon the challenges of testing custom Azure Policy definitions. Azure Policy testing still remains an open question for me, offering a lot of room for vario...
When optimizing cloud costs for large enterprise environments, it’s common to focus on compute-intensive cloud resources, such as virtual machines, clusters, and container-based workloads, as they are usually the primary cost driver and top contribut...
I recently reviewed my notes from last year’s meetings with clients and noticed that some questions about IT monitoring were repeated in almost half of the records. There was nothing special about them; they were just an essential checklist many IT Operations managers use while onboarding new services. However, the client’s response to those questions revealed some unpleasant mistakes that even mature companies make in their operations. So, let’s talk about them.

Sadly, many organizations, especially small ones, still ignore the importance of continuous service health monitoring. Some people see network, infrastructure or application monitoring as an unnecessary overhead to their business processes. Others faithfully believe that modern technologies and cloud services are so reliable that there is no need to worry about their availability.
Unfortunately, such irresponsibility has its price. If you do not know whether your computer systems operate as needed, you will have to bear the risk of loss or damage to your business. The more critical the system is, the more significant the impact of system outages. Those who survive this impact for the first time usually quickly change their mind about the monitoring process. The others, well, they do not stay in business long enough to tell us their experience.

The next most common mistake is not monitoring all your IT components end-to-end. A computer system is like an onion: its work depends on multiple layers – network, operational systems, databases, web servers, application components and even end-user devices and web browsers. Monitoring your system on one or two layers is insufficient to see the whole picture. For example, from an infrastructure perspective, everything seems fine, and all lights are green, but your users report multiple errors when accessing the application. That clearly shows you failed to implement application performance monitoring and synthetic transaction checks.
This mistake is generally observed in organizations where departments that support computer systems work separately and do not align with each other on some unified principles of operation. Typical scenarios might include teams of Devs and Ops that have different views on the core processes of running applications in production. Developers believe that their responsibility ends after an application passes all unit, integration, UI and other tests, while Operations engineers feel responsible only for providing the underlying infrastructure for the application. As a result, you have two pieces, an application package and a bunch of servers or other IT stuff, that are entirely OK on their own but completely useless as a business application.

This one is the root of all evil unsuccessful implementations of monitoring systems. Initially, it seems that the more information you gather about your computer systems, the better. However, this is not true. When you start receiving thousands of events every minute, it becomes hard to make sense of all these red lights, flags, exclamation marks, or whatever. I witnessed too many projects that monitored implementation fail due to overblown requirements to monitor everything.
That usually happens for two reasons. The first one is us, computer geeks. We are so excited about all these new cool, shiny features in this latest release of our favorite program that we want to try out all these switches, configuration options and tons of other stuff. The second one is the managers. Yes, I mean all these Dilbert-style bosses who do not make an effort, clarify objectives and effectively communicate with tech nerds. These two statements may sound harsh, but as you can see, they both point to people and do not monitor tools themselves.
So, do not blame the tools and look in the mirror if you face such an issue. Start small and then add new data only if it has value for you. The rule here is simple: if a monitoring alert, warning, or event is not of any value to you, get rid of it. If you do nothing with this data, you do not need it.

Having a lot of data from the monitoring system does not necessarily mean that you collect the data you actually need, and sometimes, in all this informational noise, people forget about the real monitoring objectives.
“There is nothing quite so useless,” said management expert Peter Drucker, “as doing with great efficiency something that should not be done at all.”
For example, you might have a server with a website running on it. You need to monitor the website’s availability for users from different regions. Novice engineers might configure an ICMP probe that will ping the server every X minutes and raise an alert if ping fails after Y attempts. Simple and effective solution, right? Wrong! ICMP ping will provide you only with the information that your server can be reached over a network, but it will not indicate whether the server listens to HTTP/HTTPS requests and serves the website content. Moreover, if you check your server availability only from your network where the monitoring system is located, you will not know if the website becomes inaccessible to users from other locations in case of network routing issues. In this example, you are getting data that does not reflect actual website availability.
The purpose of monitoring is not just to receive alerts but also to obtain information relevant to your goal.

Unfortunately, many do not understand that monitoring is not about alerts, agents, consoles and dashboards. All these are merely useless pieces of software unless there is an established Event Management process. If there is an alert with no reaction to it, no follow-up or no automated remediation, your monitoring is good for nothing.
Imagine that you invested millions of dollars and built an airport. It was constructed by the most up-to-date standards and used the most recent technologies and devices to monitor flights from its air traffic control tower. However, your ATC personnel lacks clearly defined and unified rules for assisting planes’ landings and take-offs. Each flight is expedited differently, if it is expedited at all. Some planes land successfully, some do not, and some crash into each other in the air. It looks like a bad dream, right?
I used this example to illustrate that sometimes, having even the best tools without established monitoring processes and well-trained staff can be worse than not having the monitoring at all. Well-implemented IT monitoring is about people, processes and tools. Remove one component, and I won’t give you a dime for the system you “monitor.”
What typical mistakes in IT monitoring or operation have you observed? Share your thoughts in the comments!