
Despite the common misconception, monitoring in a DevOps-aligned organization is not about “Hey, let’s use Prometheus, ELK, Grafana or whatever else and output nice dashboards on big wall-mounted screens!” Moreover, monitoring is not about tools and underlying technologies. In the first place, monitoring is about the value you are going to have from the combination of tools, processes and people in your teams.
From my experience, the implementation of even best-in-the-class monitoring solutions failed if they didn’t correspond to your internal processes, organization structure and real needs of its consumers. So, this post will be about organizational and architectural aspects rather than technical ones.
Spoiler: there is no best monitoring tool or solution on the market regardless of what salespeople can tell you.
Traditional IT monitoring
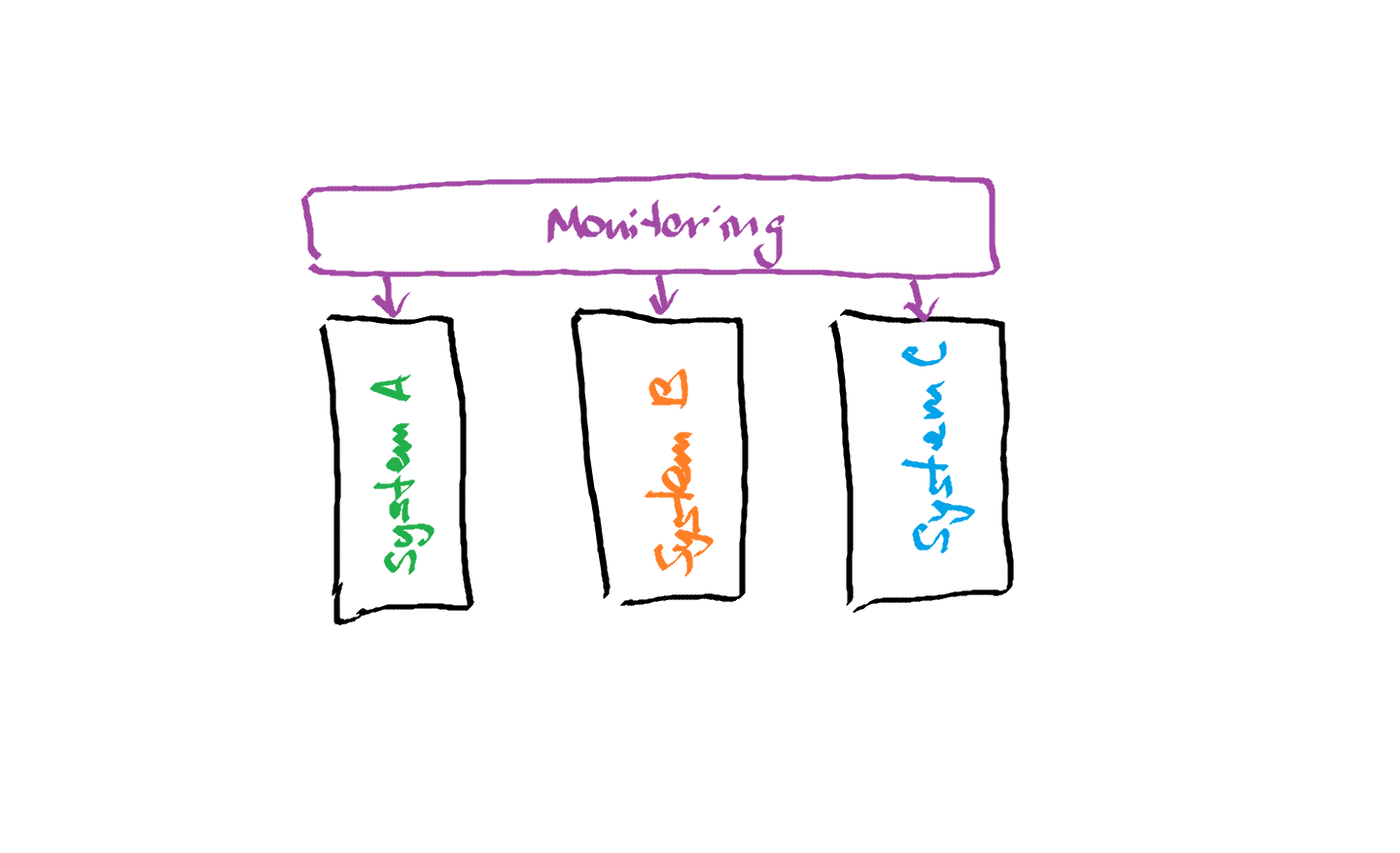
Historically, monitoring was something that the majority thought about as purely IT Operations stuff. Developers wrote code, created applications and handled them over to Ops people for deployment and running. In the best cases, both parties clarified the requirements for monitoring an app before launching it into production. In other ones, Ops just did their best trying to understand what is considered a healthy state for a specific application and configured their monitoring tools accordingly. If a new version, which contained some breaking changes, was released, the only way to avoid false-positive alerting in Operations was to deploy it into a staging environment and verify whether it is not causing an alert storm in a monitoring console.
To minimize the costs and maintenance overhead, it was common to use as few monitoring tools as possible. As usual, many organizations incorporated only one primary monitoring solution that all teams had to use as a single most relevant source of operational metrics and events. If there was a need to dig into some context-specific areas such as security, network, application performance monitoring, etc., other tools were used on-demand and usually limited to one functional team.
The primary advantage of such monitoring implementation is that you can run it with a relatively small workforce: in generic, one system requires less maintenance effort than a dozen of different tools. Also, it is easier to ensure unified user experience and standard processes for alert handling by having only one system to operate in.
On the contrary, the implementation effort for these unified monitoring tools remained quite big. As infrastructure and application environments have lots of varieties, especially on a large scale, it usually requires some trade-offs during the configuration of monitoring rules for all of them: you either have to make additional investments to tailor unsupported monitoring scenarios to your needs or just take it “as is,” with limited functionality for some of your components. Apart from that, due to their versatile nature, such ‘to-rule-them-all’ monitoring tools are quite sophisticated and require a substantial level of expertise to configure them. As a result, a small group of IT engineers who support it usually becomes a bottleneck for multiple inquiries from development teams to put some new applications on monitoring or change the configuration for an existing one.
The monitoring system becomes a sort of monolith application itself, which is hard to reconfigure, has lots of dependencies and accumulates technical debt as a high-interest credit card.
But don’t get me wrong. The described traditional approach to IT monitoring should not be considered as something ineffective or outdated. As in the application development lifecycle, it can be a perfect fit in certain environments with low change velocity such as big stable enterprises or highly regulated organizations. However, it cannot keep up with the fast flow of small and often changes, which is promoted by DevOps methodology.
The new era
A new approach to software development, which was initially promoted by Agile movement, started to gain traction from the 2010s’. Shorter development intervals, continuous changes to the product/project based on the feedback from the previous cycle, the involvement of people from different areas created new challenges to implementing monitoring solutions that now should satisfy not only the needs of operational engineers but also developers, testers, security and business representatives altogether. Moreover, each role had a different point of view on the information it would like to have from the monitoring: what can be of high interest for Ops like CPU or memory metrics has no or little value for people from marketing or sales who are more interested in tracking the number of acquired new customers or submitted orders.
So, agile teams demanded new monitoring solutions that they can easily use and reconfigure on their own without the dependency on some external party. Some vendors tried to deliver more and more functionality in their tools so to cover the needs of all product/project roles. That, however, didn’t work well as of me because it just added more complexity and created multitools that can do almost anything but not as good as specialized solutions: tools that are designated for security event management are hardly applicable for tracking business metrics.
Apart from that, you should also consider personal preferences in different teams. If a team is more familiar with a specific monitoring solution and can efficiently use in the current context, why to enforce some enterprise-scale solution on them that will slow them down ten times. Such top-down enforcement will only make your teams resistant to them and it is much better to give them freedom in toolkit choice. People are more likely to do their best with their own initiatives rather than with external motivation.
That doesn’t mean, however, that the team’s choices towards tools always be the best ones, but the essence of Agile software development is that you learn from experience and adapt. During the application lifecycle, the requirements and product vision can change so significantly from what you started with that, at some point, you might want to reevaluate your monitoring toolbox. That is totally fine and, moreover, is highly desirable. The key idea here is that your monitoring experience should change and evolve together with your application or service.
DevOps challenges
One of the ideas promoted by DevOps is to make your product or project as self-sufficient as possible. Ideally, to be able to do most of the tasks locally in your team with no or little dependency on external parties (see my Notes on “The Unicorn Project”). Besides, the idea of running services independently, which became very popular after the famous Jeff Bezos’s “API Manifesto” and followed Amazon’s success, created an organizational pattern when you can have lots of teams that operate pretty autonomously by their own internal rules.
Additionally, although it is good to have all required expertise: Devs, Ops, InfoSec, QAs, Product Owners, onboard and high-performance independent teams, it created new challenges in terms of ensuring that all these produced applications and services, especially customer-facing, are delivered according to some unified service quality levels to satisfy customer expectations.
Hint: your customers don’t care about your technical, organizational or any other internal specifics; they use your product to solve their problems.
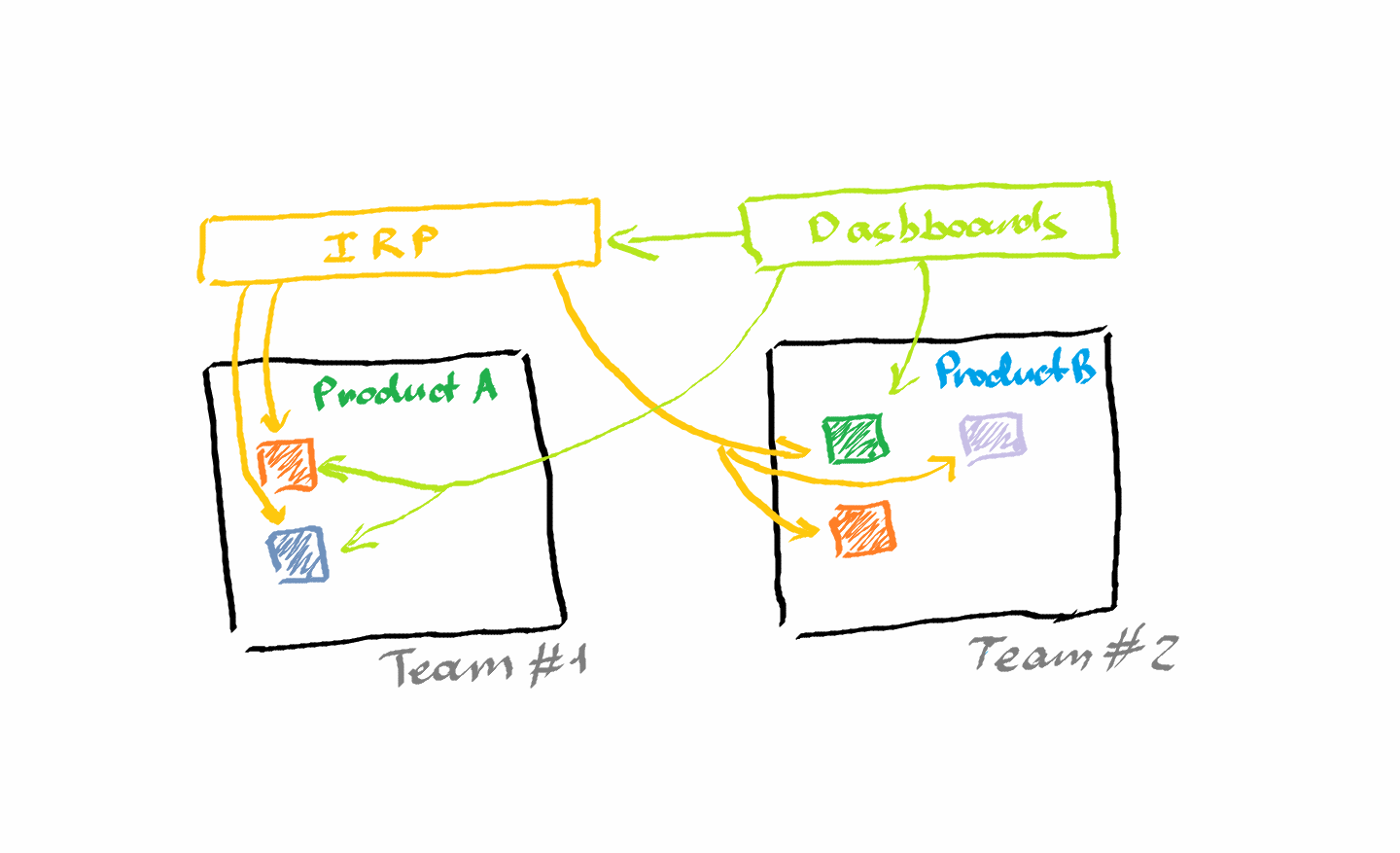
So, on the one hand, now you can have a range of applications and services that use different technology stacks, have different requirements towards their monitoring and, what’s more, might use a couple of specialized tools – one to monitor network performance, other one to track security events, yet one more to monitor user behavior, etc. On the other hand, it is ineffective to have dedicated operational centers, aka NOCs, for each product/service team taking into account the relatively small size of development teams (remember 2 pizza team rule) and the overhead for establishing and running a NOC. So, somehow, you should find a balance between the variety of monitoring tools your teams use and the efficiency of your NOC.
That challenge created a marked demand for a proper solution and such companies as PagerDuty (f. 2009), OpsGenie (f. 2012), VictorOps (f. 2012) and others responded to it with a new class of monitoring applications – incident response or incident management platforms. They were not monitoring tools per se but more like aggregators that can consume information from different monitoring solutions and streamline it in a single incident management process.
Hint: DevOps doesn’t replace ITIL, and lots of ITIL practices are necessary for a DevOps organization.
Using these aggregators, you can still employ different monitoring tools and, at the same time, have top-down visibility on incidents in all services and applications you run. The same is true for such applications as Grafana, Kibana and other data visualization solutions. They are useless on their own but really powerful in displaying data from a variety of monitoring tools they integrate with.
Even Microsoft eventually gave up on having a single operational team that monitors all company services. Instead, they started to create a monitoring toolkit that can enable other development groups to assemble custom monitoring solutions that suit their needs.
Final thoughts
Now you might start thinking how complicated all that stuff has become. If you followed the story and put all pieces of that puzzle together, now you can see that monitoring in a DevOps organization is not only about selecting the fanciest tools. It has lots of to do with your organization as well: how your monitoring process and routines should look like, who will be using that system, what data is essential for your application, what metrics your team members would like to track, how are you going to inform your internal and external customers on outages and performance degradations in your services, and many other important aspects.
How you design your monitoring solution to satisfy the business objectives towards your product or service is also crucial for the future success of your enterprise. When you can track precisely how many new users signed up to your service or how much money a new feature earned you last period, you can stop guessing and start building your product strategy on the real feedback from your customers.
As Adam Savage wrote in his book, “every tool is a hummer,” and it is a person’s hand and craftsmanship that can create a masterpiece with it. So, don’t rely blindly on yet another new cool monitoring application and always use your most valuable asset for logical thinking.

Member discussion: