Top-5 mistakes in IT Operations

A
Hey! I'm an Azure and DevOps enthusiast, PowerShell chaos monkey, avid reader and blogger. Helping people move to the Cloud.
Search for a command to run...
No comments yet. Be the first to comment.
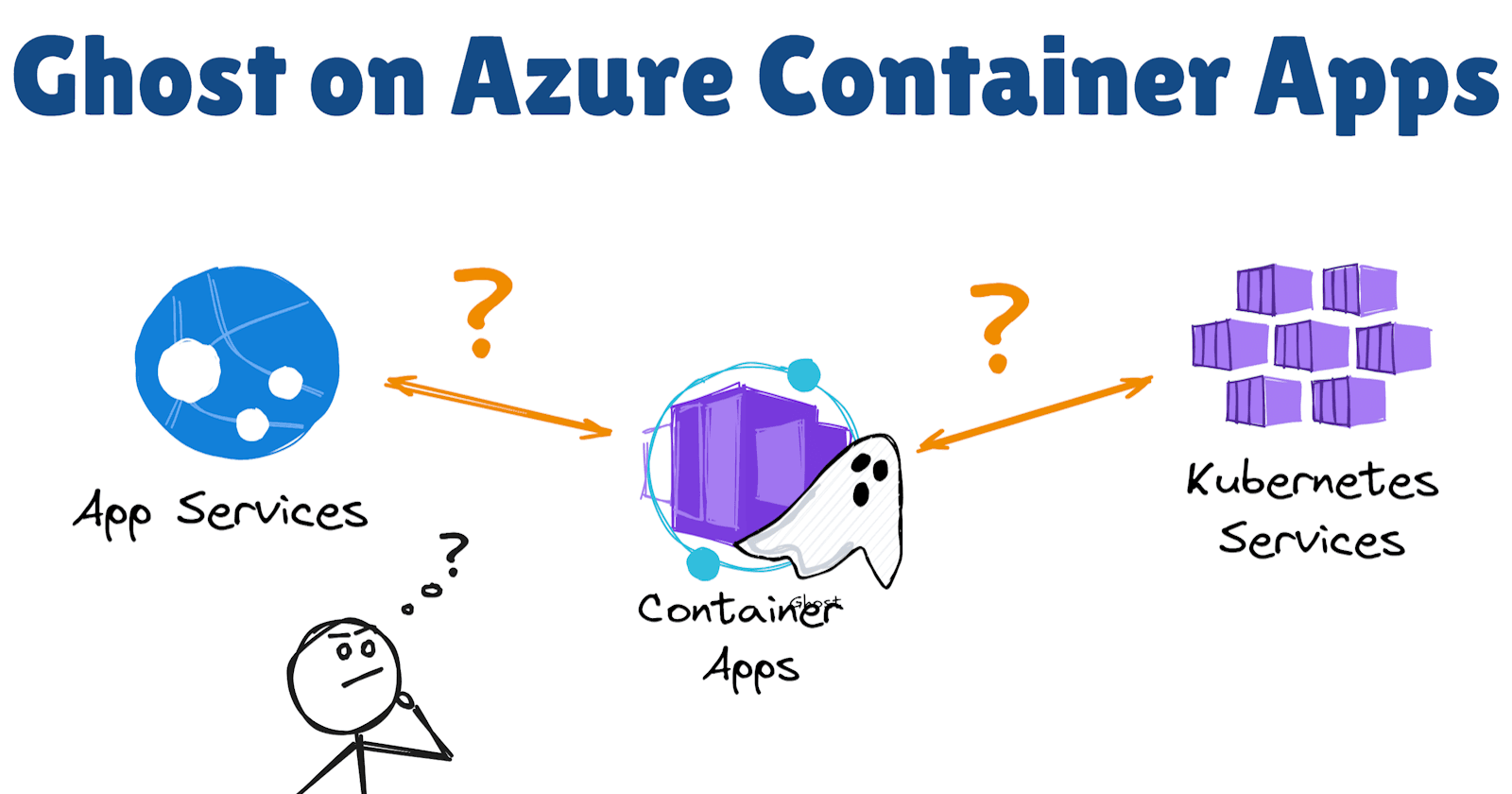
If you have been following my experiments for hosting and running Ghost on Azure, you might recall that I tried hosted it on Azure Web App for Containers first, using the Docker Compose for running a
I recently presented on a webinar hosted by the Turbo360 team and Michael Stephenson, the host of Azure on Air and FinOps on Azure podcasts. There, we discussed the most common mistakes in optimizing compute costs in Azure and how to avoid them, the ...

I’ve been watching the development of Radius, a new application hosting platform that originated in the Microsoft Azure Incubations team and later became a CNCF project, for a while, and I finally managed to dedicate some time to trying it in practic...

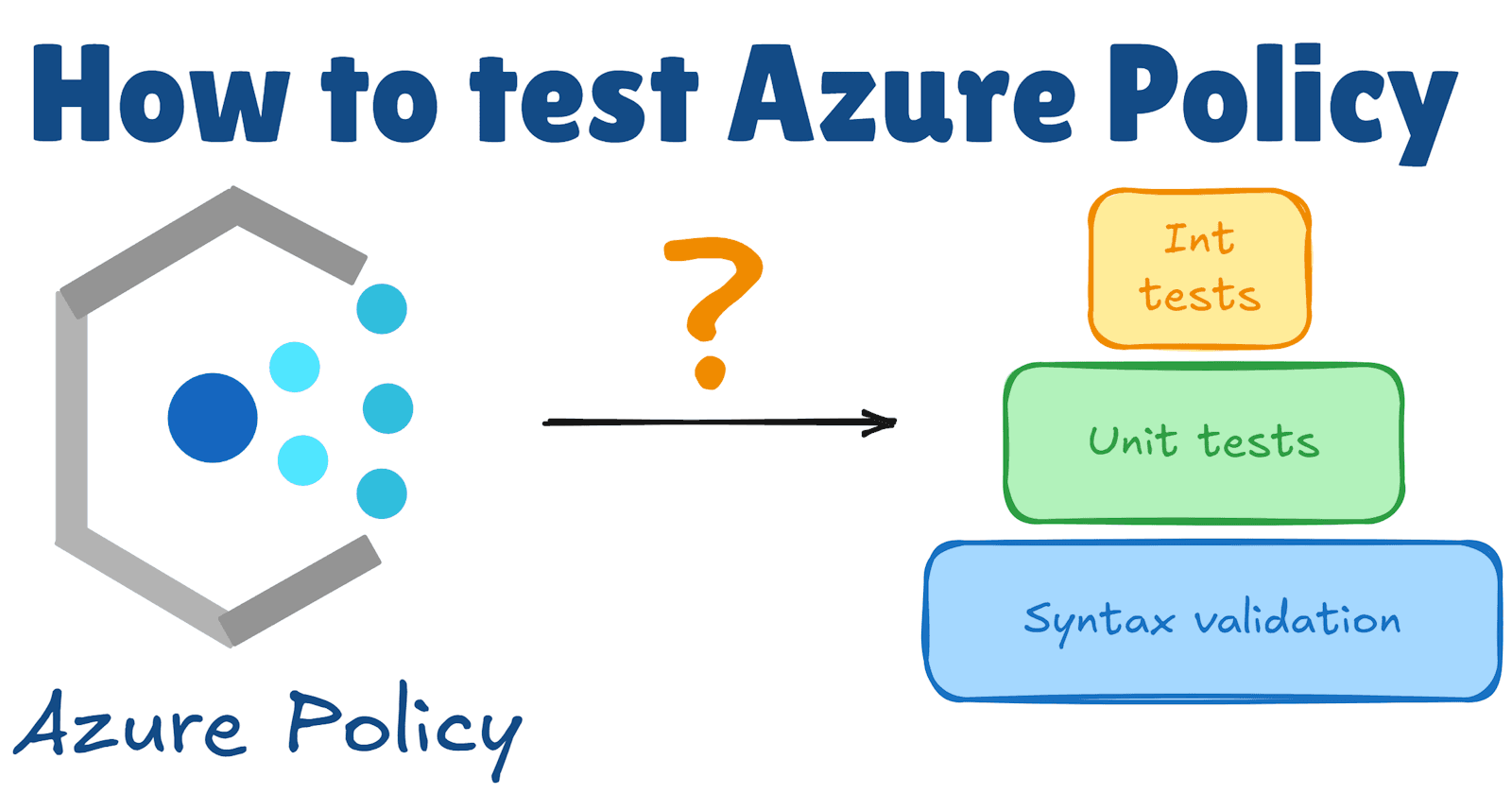
It has been some time since I wrote my Azure Policy Starter Guide, in which I briefly touched upon the challenges of testing custom Azure Policy definitions. Azure Policy testing still remains an open question for me, offering a lot of room for vario...
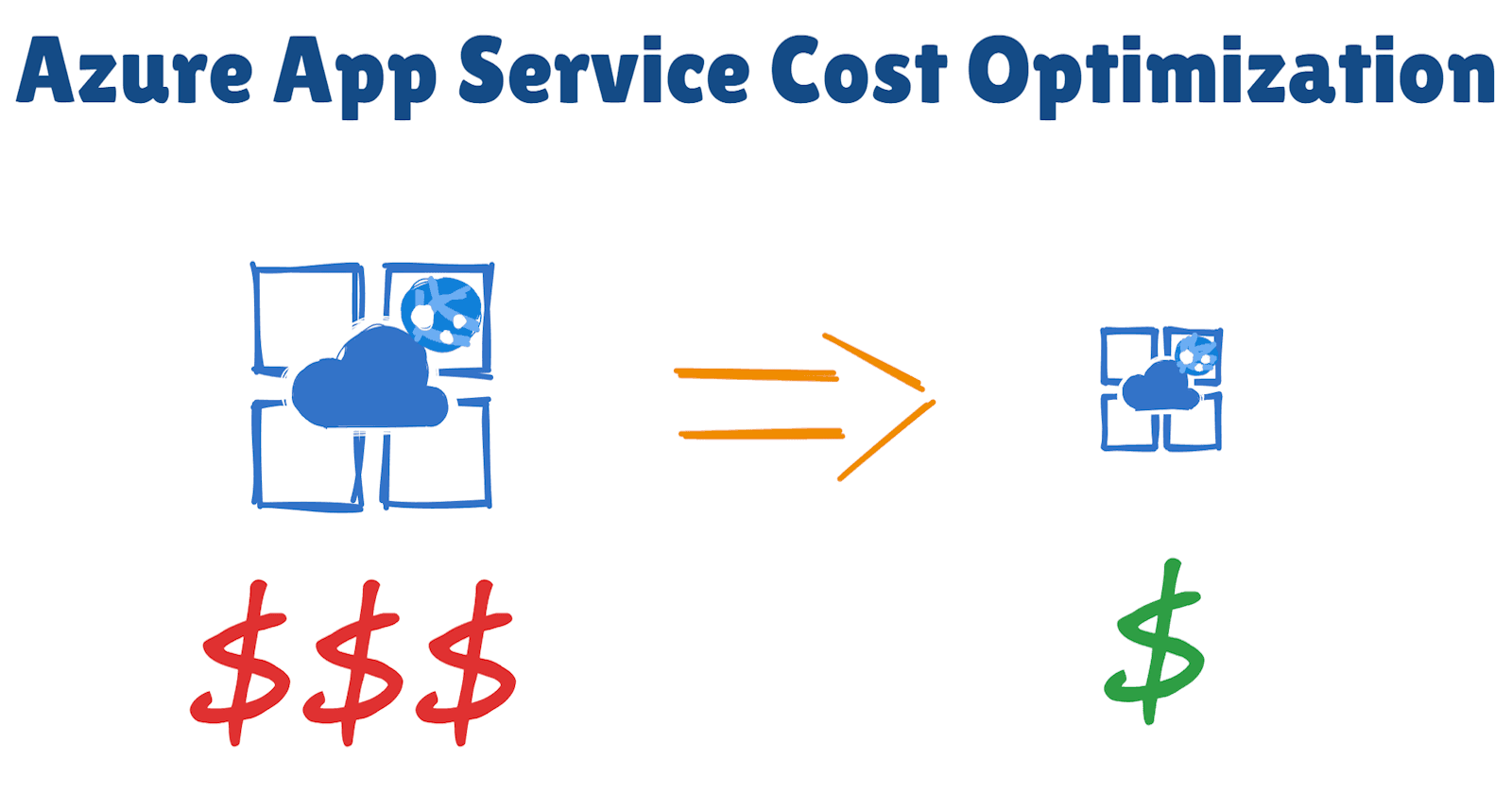
When optimizing cloud costs for large enterprise environments, it’s common to focus on compute-intensive cloud resources, such as virtual machines, clusters, and container-based workloads, as they are usually the primary cost driver and top contribut...
In this post, I would like to share my observations of the most common mistakes teams and organizations make in their day-to-day work with IT systems. This list is based on my long experience working with different customers and international teams, so you can consider it independent of location or industry.

The number one mistake is not keeping track of your work and not having a specific system for this in place. I still encounter a lot of cases, especially among small businesses, when all requests for technical support are stored as email correspondence or as stickers on monitors. A more advanced option is to have a shared Excel spreadsheet where technicians log their tasks or at least try to. Apart from the undeniable fact that these approaches do not work well at scale, they also introduce a lot of mess, conflicting tasks and unwanted downtimes.
In modern IT Operations, working without ITSM for Ops is like working without a version source control system for Devs. Even if you are the only guy or gal in operations, having the records of all support requests, changes to system configuration, and other tasks you worked on will save you a lot of time and effort in multiple cases. For example, if some IT system goes down, the first place to start your investigation is to look through the recent changes that might have affected that system. A system can return to normal in almost 80% of downtimes by simply reverting the last change. Another typical case is communication with your customers, either external or internal. Customers who can easily see and track the current state of their requests for support are less likely to call you every hour or escalate in any other way on their cases.
An essential aspect of having a good ITSM is that it becomes a reliable and trusted source of information about all your IT systems. When you can query your ITSM about the list of incidents that affected individual components of your infrastructure or the history of changes that impacted them, you can identify problem points based on factual data and not only on your gut feelings. Apart from that, if you need to onboard a new member of your operational team or perform knowledge transfer, it can be accomplished much faster because, after introducing your ITSM and its key principles, the central part of the newcomer’s learning can be self-paced.

The second most common and critical mistake is not establishing and enforcing unified operational processes. Businesses demand some level of predictability and reliability from the IT systems they depend on. Usually, these requirements are documented as Service Level Agreements (SLA) between an IT department as a service provider and other departments as customers or service consumers. If each request for support in the IT department is treated and handled differently, it is almost impossible to satisfy those requirements.
If you put yourself in the customer’s shoes, the bare minimum you expect from any service provider, except the cost, is how long it takes to have feedback on your request. Would you go to Starbucks if the wait time for your coffee varies from 5 minutes to 5 hours or 5 days each time you visit it? You can call me insane, but that is how customers often see their experience when turning to IT support for help. Instead of providing them with clear and consistent expectations, fulfilling the same type of request on each occasion takes an entirely different amount of time.
Another edge case of the same problem is having a complex operational framework that makes it hard to follow. So, instead of focusing on the value a process brings to work, people introduce additional steps or routines only for the sake of the process itself. For instance, when I see a diagram of the incident management process with 50+ steps, I know that this organization has severe issues in IT Operations. If you cannot draw your process on a single A4 paper or describe it in less than 1 minute, I doubt you can follow it daily.

I have already written an article on the top 5 mistakes in IT monitoring, but here, I would like to address the question from a broader perspective, i.e., from an operational point of view.
The worst case of insufficient monitoring is when your customers notify you first about system issues. It means you know nothing about the system state and cannot support it effectively and reliably. You cannot be trusted as a service provider.
If you do not monitor the health of your IT systems continuously, you have no means to ensure that they function according to business requirements. System support becomes a complete mess, and you entrust your future to a matter of chance. Organizations usually adopt different tools and methods to monitor their infrastructure and applications to avoid this. Unfortunately, many of them forget the need to establish a unified monitoring process and end up with incompatible tools that use different notification methods and do not provide a complete picture of incidents.
As a best practice, each IT system going to the production state must be monitored. If system configuration changes, these changes must also be reflected in the monitoring setup. Monitoring is more about the process than a single event. You cannot configure your monitoring once and forever. You have to verify and adjust it on each change to the monitored systems.

The most unpleasant part of engineering work is writing these stupid long reads that nobody will look into. That is how many technical people see this when they are tasked with writing the documentation for the system they created or configured. On the contrary, the first thing an engineer asks when working with a new system or on a new project is whether some docs can shed light on the internals of that stuff. Don’t you find this behavior a little bit confusing?
The problem is that writing and keeping documentation up-to-date requires a lot of effort and discipline from a team and its members. Due to pressure, deadlines or lack of time, this task is often abandoned in favor of “more important work.” Piece by piece, this creates a technical debt because good and explanatory documentation is a critical part of any computer system, either application or infrastructure.
Consider an example from the bus factor point of view, which I described in my Notes on “The Phoenix Project.” One of your engineers who supports a critical computer system decided to leave for some reason. They are the only person who knows everything about the system, and no such second (another engineer) or third (documentation) party shares that knowledge. How are you going to support that critical system? Sure, you can persuade this engineer to stay while you are looking for a replacement or ask them to write some manuals before leaving. In real life, neither of the above is workable: searching for a new engineer might take up to a few months, and such “exit documentation” is usually very limited and poor in quality. So, you got into trouble.
Like in programming, the not documenting systems you operate will eventually force you to pay that debt.

Due to the complexity of computer systems, operating them might require many different teams to interact and collaborate. The more people participate in a process, the harder it becomes to gather all the pieces of that puzzle and evaluate the process.
The key thing, however, is that due to changes inside an organization or outside of it, e.g., on the market, old approaches to getting the job done stop working, become ineffective, or worse—start hurting instead of helping. These changes are usually hard to observe and notice, especially if you do your part of the work and don’t see the whole picture.
One of the significant factors that we, as a human species, evolved into what we are today is adaptation. If you do not adapt to changing conditions, you will end up as dinosaurs did long ago. On the other hand, adaptation requires a lot of mental energy to change your perception and, consecutively, your behavior. Some of our primordial parts are resistant to all “unnecessary” energy expenditures, which is why people sometimes can be very reluctant to any changes in their work environment.
To overcome this reluctance challenge, you should review and evaluate all parts of your operation regularly. These reviews must target processes and systems and, most importantly, the people operating them. For many of us, it is hard to admit that, in most cases, this is we who fucked up, and that is we who should change because neither computer systems nor processes can do so on their own.